 ¡Adicto Total!
¡Adicto Total!
 9870 mensajes
9870 mensajes
|
Publicado: Sunday 07 de October de 2012, 02:33
Bueno, para tu caso, creo que esto puede servirte, lo escribí en otra web en la que escribo también:-----------------------LOS GENES NO CODIFICAN CARACTERES, CODIFICAN PROTEÍNAS.¿Por qué es importante entender esto?Mucha gente tiene la tendencia a pensar que un gen da lugar de forma invariable a un carácter. Es decir, que existe un gen de los ojos azules, un gen del pelo rubio, un gen de los brazos largos, un gen de la piel oscura… etc.Esto es absoluta y totalmente erróneo, y deriva del escasísimo conocimiento genético que tiene la población de hoy en día, cuyos conocimientos se derivan de la genética mendeliana donde se vieron estos sucesos. Los experimentos de Mendel explican la parte más sencilla de la genética, pero se quedan cortos (cortísimos) para hablar de temas más serios, como las enfermedades hereditarias de los perros, por ejemplo.Por eso es importante que quede BIEN CLARO que los genes NO DAN LUGAR a caracteres concretos, sino a proteínas. Y es la interacción de las proteínas entre ellas (o la carencia de esta interacción, en algunos casos) lo que da lugar a la mayoría de los caracteres genéticos.Para el que ande pez, un carácter es cualquier cosa que os queráis proponer. Desde el color de ojos, pasando por la altura de una persona, hasta la longitud del hueso de la mandíbula inferior o el color de la planta del pie. Todo eso está determinado, en parte por su BACKGROUND genético y en parte de forma ambiental (es decir, por el desarrollo embrionario, entre otros).Entonces, ¿qué es un gen molecularmente hablando?Una mirada hacia atrás: el DNA, ese gran desconocido.Si atendemos al DOGMA CENTRAL DE LA BIOLOGÍA MOLECULAR, propuesto por Watson y Crick a raíz de su descubrimiento de la estructura molecular del DNA (estudios por los que obtendrían el premio Nobel) se propone un flujo unidireccional de la información genética (que hoy día se ha demostrado que tiene excepciones pero que nos sirve para lo que queremos explicar).La información genética de un individuo está "guardada" en su DNA. El DNA es simplemente una molécula en forma de doble hélice formada por unidades que se emparejan con la otra hebra de manera concreta. Tenemos 4 unidades (nucleótidos) distintos, Adenina (A), Guanina (G), Citosina (C) y Timina (T). Adenina siempre empareja con Timina a través de dos puentes de hidrógeno (un tipo de enlace químico) y Citosina lo hace con Guanina a través de tres puentes de hidrógeno. Gracias a esto se forma una estructura de doble hélice levógira (que gira a izquierdas) en la que se concentra toda la información genética de un individuo. ¿Cómo es eso posible?Es sencillo, y es la base del DOGMA CENTRAL DE LA BIOLOGÍA MOLECULAR. La información contenida en el DNA está en forma de CÓDIGO, de modo que cada una de las dos hebras que forman la molécula de DNA tiene un código "de letras" formado por sus nucleótidos. Por ejemplo, el código de una hebra de DNA puede ser:AAAGCGAGTAGTGGCCATGACLos sistemas celulares saben interpretar este código y producir otras moléculas a partir de él, así es que a partir del DNA por un proceso que se conoce como TRANSCRIPCIÓN, y a través de unas enzimas (proteínas catalíticas) concretas obtenemos los distintos tipos de RNA (ribosómico, de transferencia y mensajero).¿Interpretamos el código? Fabricando proteínas.Dejaremos de lado dos de los tipos de RNA y nos interesaremos por el RNA mensajero, pues es el que principalmente dará lugar a las proteínas de los organismos.Así es que a través del proceso de TRANSCRIPCIÓN el ejemplo de código anterior puede TRANSCRIBIRSE a RNA. El RNA se diferencia del DNA básicamente en un sustituyente (una ramificación) de la ribosa que forma el nucleótido y en que no existe el nucleótido Timina, en su lugar existe el Uracilo (U), que empareja con la Adenina igual que la Timina (con dos puentes de hidrógeno). Así si nosotros fuéramos una enzima (concretamente, una RNA polimerasa), TRANSCRIBIRÍAMOS el código de la hebra anterior a RNA mensajero así:UUUCGCUCACCGGUACUGSimplemente:Donde hay A ponemos U (pues la adenina empareja con uracilo).Donde hay T ponemos A (pues la timina empareja con la adenina).Donde hay G ponemos C (pues la guanina empareja con la citosina).Donde hay C ponemos G (pues la citosina empareja con la guanina). ¿Cómo es eso posible?Es sencillo, y es la base del DOGMA CENTRAL DE LA BIOLOGÍA MOLECULAR. La información contenida en el DNA está en forma de CÓDIGO, de modo que cada una de las dos hebras que forman la molécula de DNA tiene un código "de letras" formado por sus nucleótidos. Por ejemplo, el código de una hebra de DNA puede ser:AAAGCGAGTAGTGGCCATGACLos sistemas celulares saben interpretar este código y producir otras moléculas a partir de él, así es que a partir del DNA por un proceso que se conoce como TRANSCRIPCIÓN, y a través de unas enzimas (proteínas catalíticas) concretas obtenemos los distintos tipos de RNA (ribosómico, de transferencia y mensajero).¿Interpretamos el código? Fabricando proteínas.Dejaremos de lado dos de los tipos de RNA y nos interesaremos por el RNA mensajero, pues es el que principalmente dará lugar a las proteínas de los organismos.Así es que a través del proceso de TRANSCRIPCIÓN el ejemplo de código anterior puede TRANSCRIBIRSE a RNA. El RNA se diferencia del DNA básicamente en un sustituyente (una ramificación) de la ribosa que forma el nucleótido y en que no existe el nucleótido Timina, en su lugar existe el Uracilo (U), que empareja con la Adenina igual que la Timina (con dos puentes de hidrógeno). Así si nosotros fuéramos una enzima (concretamente, una RNA polimerasa), TRANSCRIBIRÍAMOS el código de la hebra anterior a RNA mensajero así:UUUCGCUCACCGGUACUGSimplemente:Donde hay A ponemos U (pues la adenina empareja con uracilo).Donde hay T ponemos A (pues la timina empareja con la adenina).Donde hay G ponemos C (pues la guanina empareja con la citosina).Donde hay C ponemos G (pues la citosina empareja con la guanina). En la imagen se esquematiza el proceso de la transcripción. Las líneas azules representan las dos cadenas del DNA, que se mantienen superenrrolladas en condiciones normales. Durante la transcripción, mediante otras enzimas y un proceso molecular complejo se libera la tensión en la zona de interés (donde está el gen que queremos transcribir) para garantizar el acceso de la RNA polimerasa (pelota azul). La línea naranja representa el RNA mensajero que la RNA polimerasa se está encargando de generar. Como se puede observar, sólo una cadena del DNA se utiliza para la transcripción (cadena molde), la otra no se utiliza (cadena inactiva). El uso de una u otra, y en una dirección u otra dependerá de qué gen (o genes) esté la célula interesada en transcribir.Continuemos, ya tenemos el RNA mensajero… ¿De dónde sacamos la proteína?El proceso molecular de transmisión de la información génica no concluye con la transcripción, el RNA mensajero tiene que ser leído por la maquinaria celular para producir otras moléculas: las PROTEÍNAS. Este proceso se denomina TRADUCCIÓN, y se efectúa a través de la actuación de la maquinaria ribosomal de la célula (es decir, de los orgánulos celulares conocidos como “ribosomas”). En la imagen se esquematiza el proceso de la transcripción. Las líneas azules representan las dos cadenas del DNA, que se mantienen superenrrolladas en condiciones normales. Durante la transcripción, mediante otras enzimas y un proceso molecular complejo se libera la tensión en la zona de interés (donde está el gen que queremos transcribir) para garantizar el acceso de la RNA polimerasa (pelota azul). La línea naranja representa el RNA mensajero que la RNA polimerasa se está encargando de generar. Como se puede observar, sólo una cadena del DNA se utiliza para la transcripción (cadena molde), la otra no se utiliza (cadena inactiva). El uso de una u otra, y en una dirección u otra dependerá de qué gen (o genes) esté la célula interesada en transcribir.Continuemos, ya tenemos el RNA mensajero… ¿De dónde sacamos la proteína?El proceso molecular de transmisión de la información génica no concluye con la transcripción, el RNA mensajero tiene que ser leído por la maquinaria celular para producir otras moléculas: las PROTEÍNAS. Este proceso se denomina TRADUCCIÓN, y se efectúa a través de la actuación de la maquinaria ribosomal de la célula (es decir, de los orgánulos celulares conocidos como “ribosomas”).  La imagen muestra la estructura de un ribosoma. Está formado por dos subunidades que se conocen como “subunidad grande” y “subunidad pequeña”. Durante el proceso de traducción el ribosoma “lee” la hebra de RNA mensajero formada durante la traducción y construye una cadena peptídico a partir de ella, que dará lugar a una proteína.Así, el RNA mensajero es leído y se produce la proteína mediante el uso de los aminoácidos, unas moléculas peptídicas que producimos en el cuerpo o ingerimos con la dieta (aminoácidos esenciales). Así, mediante la maquinaria celular un RNA mensajero es convertido a proteína mediante la interpretación del código genético (que es universal): La imagen muestra la estructura de un ribosoma. Está formado por dos subunidades que se conocen como “subunidad grande” y “subunidad pequeña”. Durante el proceso de traducción el ribosoma “lee” la hebra de RNA mensajero formada durante la traducción y construye una cadena peptídico a partir de ella, que dará lugar a una proteína.Así, el RNA mensajero es leído y se produce la proteína mediante el uso de los aminoácidos, unas moléculas peptídicas que producimos en el cuerpo o ingerimos con la dieta (aminoácidos esenciales). Así, mediante la maquinaria celular un RNA mensajero es convertido a proteína mediante la interpretación del código genético (que es universal): La imagen superior esquematiza el código genético. Este se lee en “codones”, o lo que es lo mismo “en grupos de tres nucleótidos”. Como se ve en la imagen, los distintos codones dan lugar a un aminoácido concreto. Por ejemplo: UUU y UUC codifican el aminoácido Fen (fenilalanina).Siguiendo el ejemplo anterior, nuestra hebra era:UUUCGCUCACCGGUACUGLa separamos en grupos de tres codones:UUU // CGC // UCA // CCG // GUA // CUGY miramos qué aminoácido codifican con el código genético. Obteniendo:Fen – Arg – Ser – Pro – Val – LeuLos aminoácidos que aparecen, por si no conocéis la abreviatura son: fenialanina (Fen), arginina (Arg), serina (Ser), prolina (Pro), valina (Val) y leucina (Leu).Con esto la célula tendría su PROTEÍNA CONSTRUIDA (interpretada desde su código genético), que mediante los mecanismos apropiados (con ayuda de otras proteínas llamadas chaperonas) se plegaría para tener la estructura correcta y ejercer su función en la célula (por ejemplo, puede ser una proteína que forme un canal de calcio dimérico que se abra al unir su ligando liberando el calcio intracelular).----------------------------Creo que este texto puede responder tus dudas, si no entiendes algo, o tienes más preguntas, no te cortes: pregunta. La imagen superior esquematiza el código genético. Este se lee en “codones”, o lo que es lo mismo “en grupos de tres nucleótidos”. Como se ve en la imagen, los distintos codones dan lugar a un aminoácido concreto. Por ejemplo: UUU y UUC codifican el aminoácido Fen (fenilalanina).Siguiendo el ejemplo anterior, nuestra hebra era:UUUCGCUCACCGGUACUGLa separamos en grupos de tres codones:UUU // CGC // UCA // CCG // GUA // CUGY miramos qué aminoácido codifican con el código genético. Obteniendo:Fen – Arg – Ser – Pro – Val – LeuLos aminoácidos que aparecen, por si no conocéis la abreviatura son: fenialanina (Fen), arginina (Arg), serina (Ser), prolina (Pro), valina (Val) y leucina (Leu).Con esto la célula tendría su PROTEÍNA CONSTRUIDA (interpretada desde su código genético), que mediante los mecanismos apropiados (con ayuda de otras proteínas llamadas chaperonas) se plegaría para tener la estructura correcta y ejercer su función en la célula (por ejemplo, puede ser una proteína que forme un canal de calcio dimérico que se abra al unir su ligando liberando el calcio intracelular).----------------------------Creo que este texto puede responder tus dudas, si no entiendes algo, o tienes más preguntas, no te cortes: pregunta. |
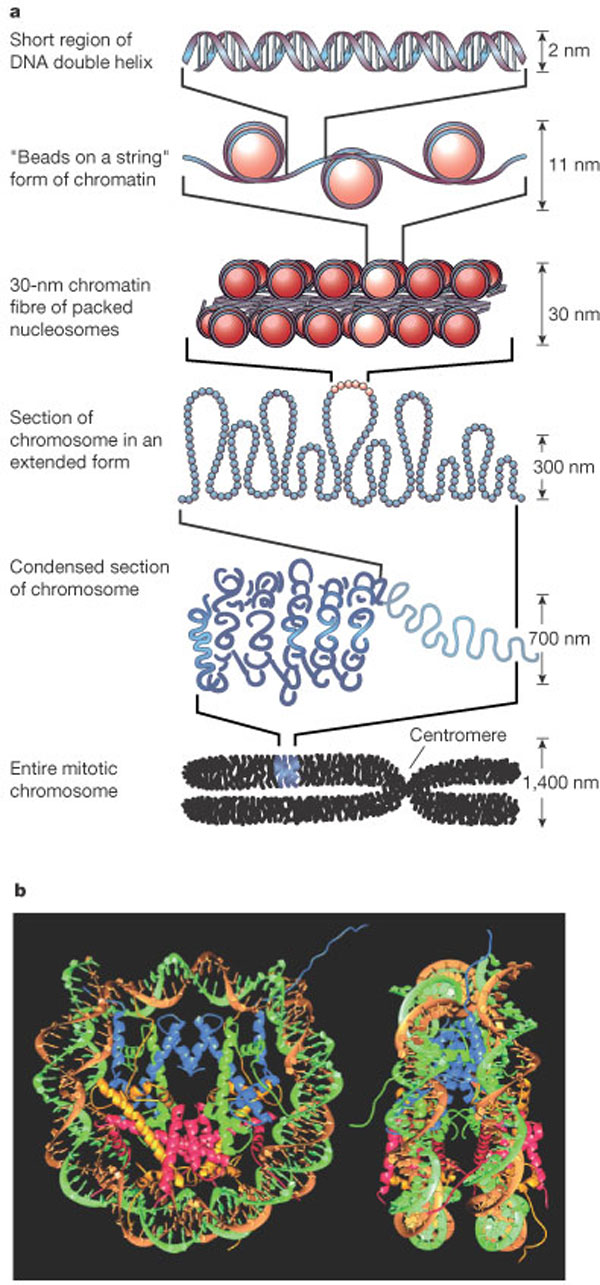 Yo estoy hablando de procesos que ocurren en los primeros niveles de la imagen, y tú del último (en la X del final, una de las aspas es una cromátida).
Yo estoy hablando de procesos que ocurren en los primeros niveles de la imagen, y tú del último (en la X del final, una de las aspas es una cromátida).  muy buen ejemplo.Yo estoy en pañales en genetica, y en el libro tambien se habla de la informacion no valida, cuando lo he leido me plantee, que quizas no es que no sea valida o no codifique nada sino que no hemos descubierto su funcion ya que observando a la "madre naturaleza" podriamos decir que es una ahorradora de recursos.Gracias de nuevo por el articulo, en cuanto tenga dudas (seguro que en cuanto retome el estudio en plan mas serio) las pregunto.
muy buen ejemplo.Yo estoy en pañales en genetica, y en el libro tambien se habla de la informacion no valida, cuando lo he leido me plantee, que quizas no es que no sea valida o no codifique nada sino que no hemos descubierto su funcion ya que observando a la "madre naturaleza" podriamos decir que es una ahorradora de recursos.Gracias de nuevo por el articulo, en cuanto tenga dudas (seguro que en cuanto retome el estudio en plan mas serio) las pregunto. 

 Pastor alemán|Bulldog|Bull terrier|Yorkshire|Boxer|San bernardo|Schnauzer|Golden Retriever|Doberman|Labrador Retriever
Pastor alemán|Bulldog|Bull terrier|Yorkshire|Boxer|San bernardo|Schnauzer|Golden Retriever|Doberman|Labrador Retriever


